ECE 5554 / ECE 4554: Computer Vision Fall 2018
Instructions
Due date: 11:55pm on Wed, November 28, 2018
Handin: through Canvas
Starter code and data: hw5.zip
Deliverables:
Please prepare your answer sheet using the filename of FirstName_LastName_HW5.pdf.
Include all the code you implement in each problem. Remember to set relative paths so that we can run your code out of the box.
Compress the code and answer sheet into FirstName_LastName_HW5.zip before uploading it to canvas.
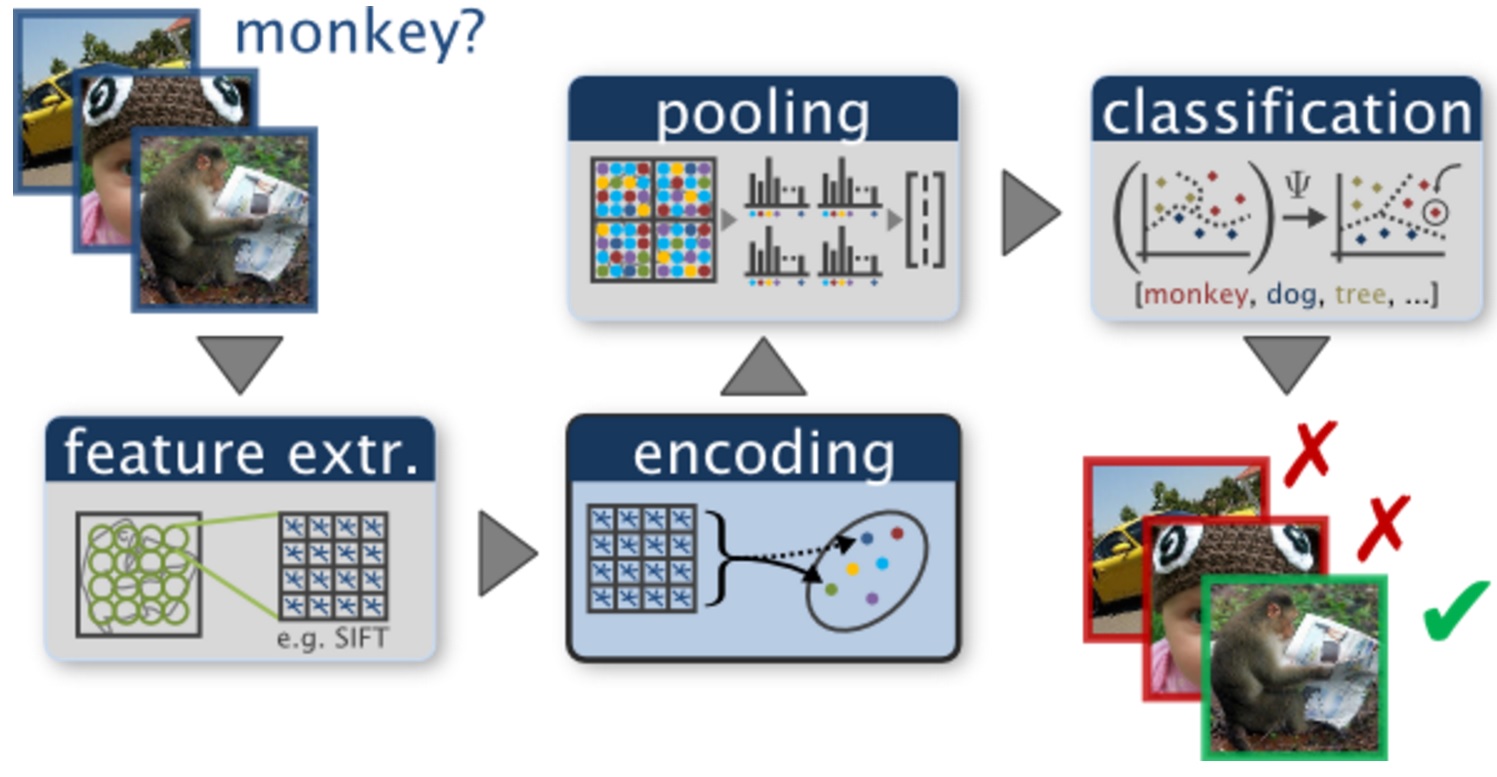
Scene Cateogrization (100 points)
 |
The goal of this assignment is to introduce you to image categorization. We will focus on the task of scene categorization. You task is to implement image features, train a classifier using the training samples, and then evaluate the the classifier on the test set.
Dataset: In the supplemental material, we have supplied images with 8 outdoor scene categories: coast, mountain, forest, open country, street, inside city, tall buildings and highways. The dataset has been split into a train set (1888 images) and test set (800 images), placed in train and test folders separately. The associated labels are stored in gs.mat, for example, label id of 42.jpg in the training folder corresponds to train_gs(42). Its actual label name will be names{train_gs(42)}.
A. Color histogram and k-nearest neighbor (kNN) classifier (25 points)
Implement a function to compute the color histogram of an image. For example, you can use the Matlab function hist for computing marginal histogram of RGB channels.
Use nearest neighbor classifier (kNN) to categorize the test images.
B. Bag of visual words model and nearest neighbor classifier (25 points)
Implement K-means cluster algorithm to compute visual word dictionary. The feature dimension of SIFT features is 128.
Use the included SIFT word descriptors included in sift_desc.mat to build bag of visual words as your image representation.
Use nearest neighbor classifier (kNN) to categorize the test images.
C. Bag of visual words model and a discriminative classifier (25 points)
Use the bag of visual word representation.
Replace the nearest neighbor classifier with SVM classifer. Use 1 vs. all SVM for training the multi-class classifier.
D. CNN model and a discriminative classifier (25 points)
Using pre-trained convolutional neural network as a feature extractor and a SVM for scene categorization. You can use the ConvNet library in MATLAB MatConvNet with one of the pre-trained classification models here.
Use 1 vs. all SVM classifier to categorize the test images
Write-up
(25 points) A. Color histogram and k-nearest neighbor (kNN) classifier
Describe your quntization/binning method and parameters
Report number of K for the kNN classifer
Display the confusion matrix and categorization accuracy.
(25 points) B. Bag of visual words model and nearest neighbor classifier
Describe the number of visual words you use, K-means stopping criterion, and the categorization accuracy.
Display the confusion matrix and categorization accuracy.
(25 points) C. Bag of visual words model and a discriminative classifier
Report the training time and testing time for SVM
Display the confusion matrix and categorization accuracy.
(25 points) D. CNN as features and a discriminative classifier
Describe the model you used.
Display the confusion matrix and categorization accuracy.
Hint
You cannot use built-in or external implementation of K-Means algorithm.
Useful MATLAB function
hist: for building the histogram for color and bag of visual words.
pdist2: for finding nearest neighbor
KDTreeSearcher: for efficient nearest neighbor search
fitcsvm, : for training a SVM
Graduate credit (max possible 30 points extra credit)
up to 10 points: Use “soft assignment” to assign visual words to histogram bins. Each visual word will cast a distance-weighted vote to multiple bins.
up to 10 points: Implement one of the advanced feature encoding, e.g. fisher vector encoding, super vector, or LLC. See The devil is in the details: an evaluation of recent feature encoding methods, BMVC 2011 for more details. Compare the results with that from (C). You can use built-in Gaussian mixture models in MATLAB if you want to implement the fisher vector encoding.
 |
up to 10 points: For bag of visual word models, experiment with different number of visual word, e.g. K = 25, 50, 100, 200, 400, 800, 1600. Report the categorization accuracy for each K.
up to 10 points: Try using two different pre-trained CNN models. Report the accuracy of each of the models.
up to 10 points: For one specific CNN model (e.g., AlexNet or VGGNet), report the classification accuracy when you use different levels of feature activations, e.g., Pool4, Pool5, Fc6, Fc7.
In your answer sheet, describe the extra points under a separate heading.
Acknowledgements
This homework is adapted from the projects developed by Derek Hoiem (UIUC).