Parallel Matrix Factorization for Recommender Systems using Social Network Information
Yao Zhang, Liangzhe ChenSpring 2014 ECE 6504 Probabilistic Graphical Models: Class Project
Virginia Tech
Goal
The goal of our project is to integrate social network information with the classic matrix factorization to build a recommender system which predicts the preference of a user more accurately.The basic of our project is the recommender system. Companies like Amazon, Hulu, use recommender systems to predict their customers preference towards certain product based on their previous purchase, and recommend products with high value to customers. The more accurate the system can predict customers' preference, the more profit it brings.

Approach
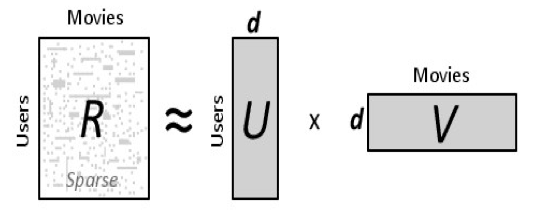
We first look at the classic matrix factorization. The dataset we have is a n by d matrix R, n is the number of users and d is the number of items. R(i,j) is the rating for item j from user i. In this matrix, typically there are many missing data because every user only rate very limited number of items. The task here is to reconstruct and complete the matrix so the value we fill in these missing part is consistent with the other data points already in the matrix.The intuition behind matrix factorization is that there should be some latent rules by which users rate item, and we capture this latent rules by factorizing the original data matrix to two parts, one represents how users are connected to certain rules, and the other represents how certain rules are connected to items. As shown in the following picture:
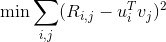
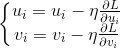
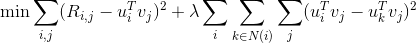
Results
The dataset we use for our problem is from Movielens. It contains 1,000 users, 1,700 movies, and 100k rates. This dataset can be downloaded from this link: http://grouplens.org/datasets/movielens/. In this dataset, we don't have friendship relation between users, so we build a social network between users using the similarity of their rating. If the ratings from two users are similar then we regard them as friends.The parameter setting for our experiment is: learning rate 0.01, number of latent rules is 20 (which is part of the size of U and V), 10 blocks when parallelizing. All codes are implemented in python, we use python multi-threads to simulate the parallelization.
We use mean squre error (MSE) to measure the performance. Lower is better. We first ran our algorithms on the whole dataset, and calculated the MSE (Training Error). Then we divided the dataset into two parts: 80% as training data and 20% as testing data, and calculated the MSE (Testing Error).
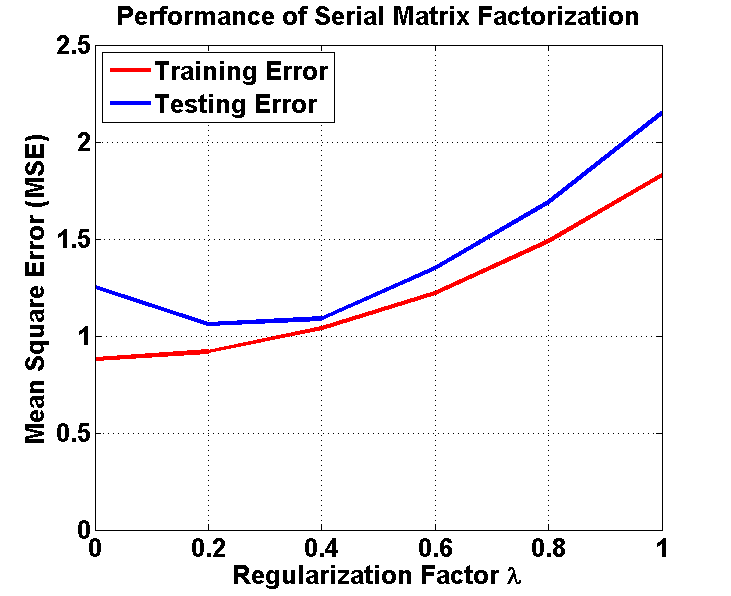
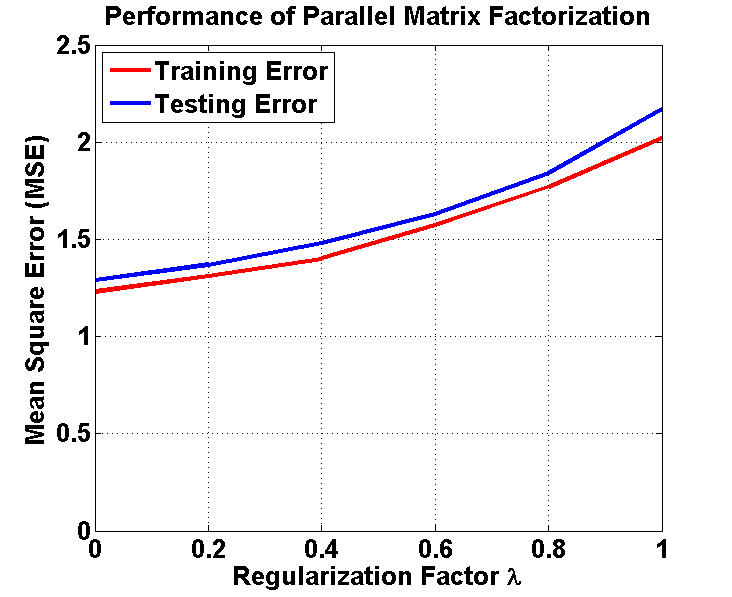
Here's some observation from our results. First, for both serial and parallel matrix factorization, the training errors are always lower than the testing errors. Second, the serial matrix factorization is better than the parallel version. This is because we may loss some information using the current parallel algorithm (we only consider blocks in the diagonal of the original matrix). Third, as the regularzition factor increases, for the serial algorithm, the testing error first becomes smaller, then increases, which means our regularization works. Also, the best result we get from serial version of our algorithm has RMSE=0.94, and MSE=0.88.
Here's the running time of our algorithm:
Serial Matrix Factorization: running time: 19.90s
Parallel Matrix Factorization: runnint time: 2.19s
Parallel Matrix Factorization algorithm is nearly ten times faster than serial matrix factorization algorithm.