Understanding and Predicting Importance In Abstract Images
Shanmukha Ramakrishna VedantamSpring 2014 ECE 6504 Probabilistic Graphical Models: Class Project
Virginia Tech

Goal
The goal of this project is to predict importance of an object in an image. An object in the image is called important if it also gets mentioned in a sentence describing it.Why do people mention some objects in a sentence and not others? The notion of importance is in a lot of ways central to true semantic understanding of images. A related concept of saliency has been widely studied in computer vision literature but that is mostly at a low level of features. Importance, on the other hand focuses on objects and is thus much closer to a notion of semantic saliency. Previous work on importance uses location, and basic context features such as attribute-scene-object relationships. This project is an attempt to study importance with more semantic features such as gaze, expression and pose. Also, contrary to the previous work, I employ a conditional random field model to incorporate inter object importance dependencies. I use a dataset of Abstract images with rich semantic feature annotation to facilitate this study (see Fig. above). This dataset has eight categories (sky objects, large objects, boy, girl, clothing, food, toys) and 58 object instances.
Approach
Computing ImportanceImportance is computed by a soft membership score of an object to a sentence. This score is then averaged over multiple sentences. Importance is also computed over categories by averaging the object importance scores.
Predicting Importance The importance predictions are made using a CRF model where each node represents an object in the image.

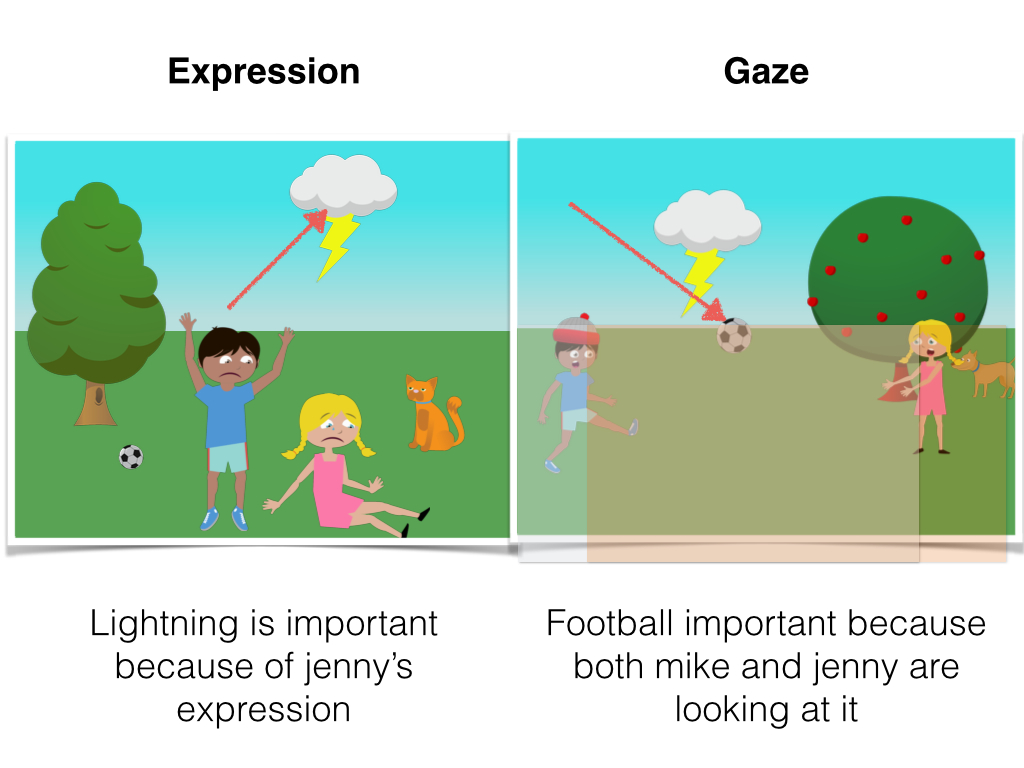
The semantic potential is learnt on features indicating gaze, pose, expression and object category. More specifically, histogram counts of number of objects in a particular pose (out of seven poses) and number of objects in a particular expression (out of five expressions) are used. These features are appended with a gaze feature which counts if the object is present in the gaze field of other objects in the image (see Fig. below). Further, the category feature is an indicator vector appended to the semantic feature set indicating 1 for the category to which the node belongs to.
The location features are x, y, and depth for an object augmented with an indicator vector for object id in the dataset, which specifies the object. Using both location and semantic features, an SVM is trained and the confidences given by it are used as node potentials in the CRF, with parameters alpha and beta combining them.
The edge potentials have three variants. Two of them are text based potentials which look at object co-occurrence in sentences. That is we try to measure how correlated the importances of two objects were, by crawling over a large collection of 5000 Abstract Images each annotated with 1 sentence each. Given these values, the co-occurrences were set on the 00, 11 entries of the edge potentials. The other two entries of the edge potential were set to zero. These are called correlation potentials. The other kind of text based potentials measure how likely a state in the edge potential table is. The importance scores per object instance per image are taken as probabilities and the average probability of two objects occurring in four possible importance states is computed. These are called probability potentials. The third kind of edge potentials are based on distance in location feature space. These are called image based potentials.
Given the node and edge potentials, a natural question is how the CRF will be connected. Two possible connection schemes were investigated. The first was a fully connected CRF and the second was a sparse CRF with edges only between nodes which belonged to the same category in the dataset.
The inference routine was Iterated Conditional Modes and the parameters were set through grid search on a validation set. Importance was learnt from a set of 300 training images with 50 sentences each. The test and val set were 100 images each.
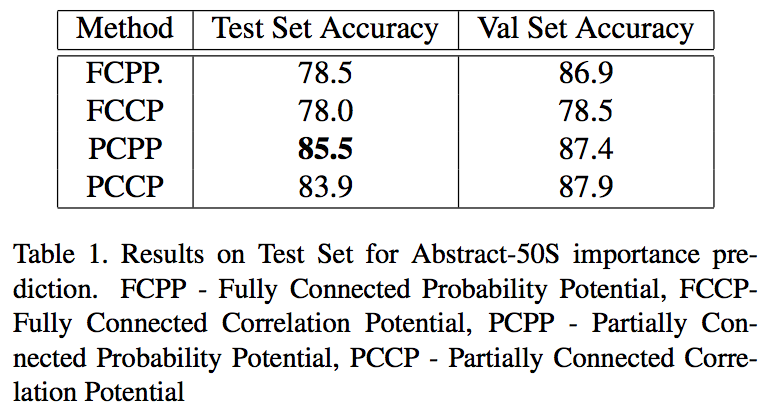
Results
Importance Results: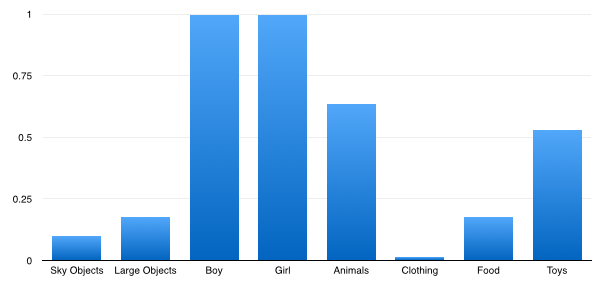
Prediction Baselines: Four baselines are considered. The first is random, where an object is always predicted as unimpor- tant. This gives an accuracy of 53 %. The second baseline predicts mike and jenny to be always important. This gives an accuracy of 81.13 %. The third baseline considers average cate- gory importance across the dataset. This gives an accuracy of 83.6 %. The final baseline is an instance level importance, which calls an object as important if on average it is important more often than not across the dataset. This gives an accuracy of 87.4 %.
Prediction Results: The partially connected CRF model with probability potentials performs the best at 85.5 % accuracy on the test set. The node potentials for semantic features perform at 85.2 % accuracy. This represents a boost of 0.3 % from using the CRF. Further, the location based edge potentials give a performance of 63.4 %. Thus the semantic features do much better than the location features. However, the instance level importance baseline proves to be really tough to beat for all cases, giving an accuracy of 87.4 %. The results with Image based edge potentials are much lower, at 67.2 % accuracy. Key results are summarized below.