Shrenik Lad Spring 2014 ECE 6504 Probabilistic Graphical Models: Class Project Virginia Tech
Goal
In this work, we propose a method to create intelligent as well as interpretable classification systems. Image classification systems are generally trained in low-level feature spaces as these features are shown to perform well on several recognition and scene understanding tasks. But as more and more sophisticated features and classifiers are introduced, the classification system becomes less interpretable. We propose a novel approach for training any classification system such that its decisions are semantically interpretable. Specifically, we use the combination of semantic attributes and a single decision tree to understand
the decisions of a classifier. For eg, our approach allows us to discover concepts that classifier has learned like "furry, eyes, and legs imply dog", "handlebars, no window, wheels imply motorbike". Such a rich understanding of our systems can help us to communicate with machines in a better way. It also makes debugging of classification systems easier because we know what exactly the classifier has learned and what it is missing. We propose a novel semantic confidence measure using our interpretable model that can be given at test time along with the classifier's prediction. We conducted experiments on the aPascal dataset and achieved encouraging results.
Approach
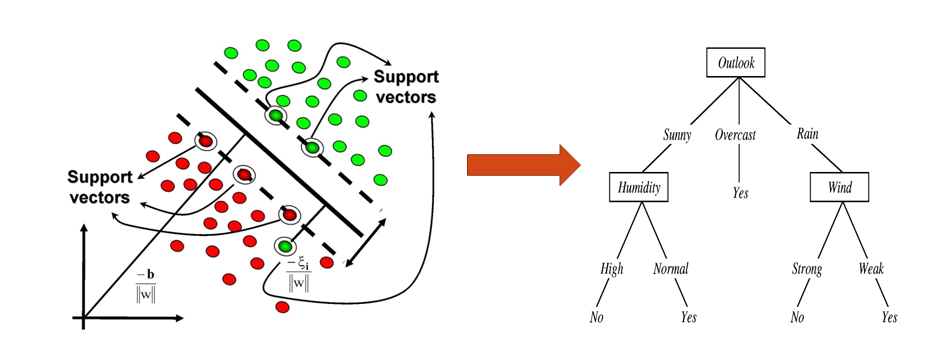
We use semantic attributes and decision tree to understand a classification system (lets call it BaseSys). The BaseSys could be any classifier that learns from low-level features. Our interpretable model (decision trees + attributes) tries to mimic the BaseSys and so the various paths/rules in learned decision tree would tell us the rationale of BaseSys for various predictions.
We assume a semantic vocabulary of M attributes is pre-defined. Given N training images and GT attribute annotations on each of them, the stepwise procedure is as follows :
Train the BaseSys using low-level features
Do J-fold cross validation of BaseSys (with some fixed parameter) and this gives us predictions of BaseSys on the entire training set
Train a Decision Tree (DT) in attributes space using BaseSys predictions as ground truth (GT)
Every path in the decision tree gives us a rationale for particular prediction. An illustration of above approach is given below:
.
Intelligence comes from BaseSys and interpretability is inherently there in our model
Our approach can also be seen as doing Variational Inference. If P is the class of "Intelligent" classifiers (strong learners, low-level features, etc), and Q is the class of "Interpretable" classifiers (DT + Attributes in our case), we are mapping any given classifier in P to another classifier in Q. Establishing exact theoretical connection between our approach and variational inference is part of future work.
We explored two scenarios for BaseSys and present a semantic confidence for both:
BaseSys - Multi-Class
In the case of multi-class BaseSys with K categories, we do J-fold cross-validation and get predictions on training data. Instead of training a single multi-class decision tree, we train in a one vs. rest fashion. We train K decision trees, each DT(k) trying to understand BaseSys with respect to a single category. The reason is that a multi-class DT could be very deep and hence not interpretable at all. The positive instances for DT(k) are images that were predicted as category k by BaseSys, and all other images are used as negative instances. A perfect DT(k) is one which predicts 1 whenever BaseSys predicts category k and 0 whenever BaseSys predicts category not equal to k.
BaseSys - Binary
In case of binary classification, BaseSys is trying to learn a single concept using positive and negative examples. The predictions of BaseSys are directly fed to a DT. A perfect DT is one which predicts 1 whenever BaseSys predicts 1 and vice-versa.
Semantic Confidence
We propose a semantic confidence measure that can be given at test time along with predictions on novel images. A traditional margin based confidence given by BaseSys is not a good indicator because it is derived from low-level features and there is no semantic reasoning. On the other hand, attributes are good for describing objects, so if BaseSys predicts an image as Dog and if the image has attributes furry, eyes, legs etc, we can give a high confidence for the prediction. We compute semantic confidence as follows:
Run each training image through the learned DT
For each leaf node, count how many correctly predicted images (by BaseSys) fell into the node
Normalize the counts at each node to lie between 0 and 1. These counts are basically the confidences of the corresponding paths in DT
Good paths of a DT (for eg: ''sand, water, sky imply beach'') will have high confidences and bad paths (for eg: ''tiles, wood, furniture imply dog'') will have low confidences. At test time, we run the novel image through the DT and assign a semantic confidence based on the leaf node where it falls.
Results
We use the aPascal dataset for our experiments. Our train set has 2700 images and test set has 2700 images including all 20 Pascal categories. There are 64 semantic attributes. For BaseSys, we train a linear SVM using LibSVM library. We do leave one out cross validation (LOOCV) for multi-class and 12 fold cross validation for binary classification.
Qualitative results
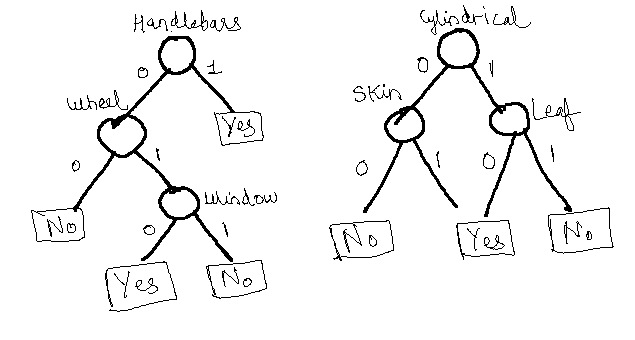
Here are some decision trees generated through our approach. The following figure shows decision trees for motorbike (left) and bottle (right) categories. We see that handlebars and wheels are important to predict motorbikes. We also see that the classifier has associated skin property with bottle because most of the training images had a person holding a bottle.
Quantitative evaluation - Semantic Confidence
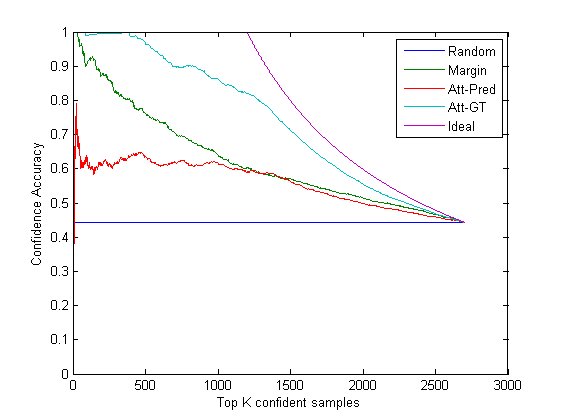
Semantic confidence is evaluated as follows. We sort the test images according to the confidence values. We create a plot of accuracy vs. T which indicates how many of the top T confident predictions were correct.
We compare the following confidence measures:
Random (random confidence results in a constant plot = accuracy of BaseSys on test)
Margin (margin based confidence given by SVM)
Attr-Pred (Uses attribute predictions on images at test time)
Attr-GT (Uses GT attributes of images at test time. Upper bound of our approach)
Ideal (confidence = 1 for correct predictions, confidence = 0 for incorrect)
Following are the results for multi-class scenario. We see that the oracle version of our approach (Attr-GT) performs close to ideal while the realistic baseline Attr-Pred performs poor than margin. We need to make our method robust to noisy attribute predictions.
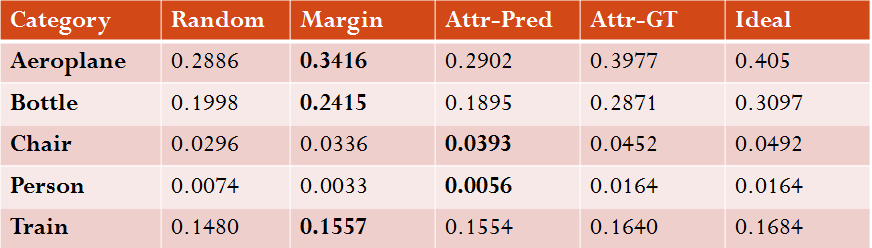
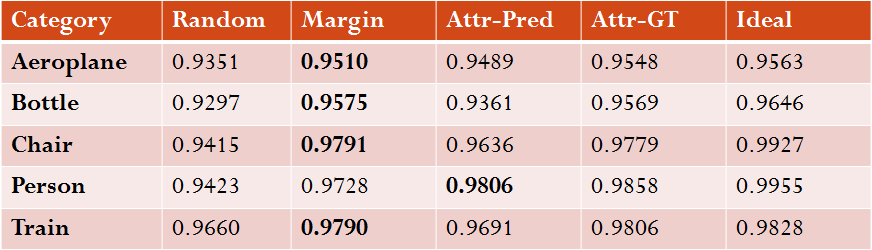
In case of binary classification, each category has its own confidence comparison plot, so we summarize each plot by area under the curve (AUC) for all baselines. The higher the better. Results for 5 randomly chosen categories are shown below. We are interested in the performance of margin vs Attr-Pred and the higher performance between the two is highlighted. As we can see, Margin outpeforms Attr-Pred most of the times while Attr-GT is close to ideal
Comparison of confidences for positive predictions
Comparison of confidences for negative predictions
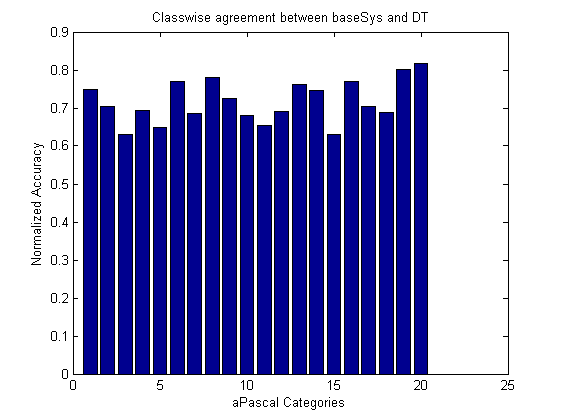
Quantitative evaluation - Agreement between DT and BaseSys
Following is the categoywise agreement of our interpretable model (DT + Attibutes) with the BaseSys. The agreement is computed as Normalized accuracy = (TPR + TNR) / 2. On an average, the agreement was around 70%, which means that the rules discovered by our model can be trusted.