Node Classification in Social Networks
Sorour Ekhtiari AmiriSpring 2014 ECE 6504 Probabilistic Graphical Models: Class Project
Virginia Tech
Goal
| The
goal of this project is classifying nodes in graphs considering its
position in the graph. Classic machine learning classification
techniques assume that the label of each object is independent from
others, however in a graph this assumption is not true and connected
nodes will probably be in the same class. In other words, we cannot
assume the label of each node as an independent entity from other
nodes. For instance in a graph of friendship if a person is infected,
her\his friends will have higher probability of infection. Another
example can be in scientific paper author graphs, which represent the
connection between nodes of the graph when they have at least one
common author. In this data set the topic of connected papers are
probably the same. In these 2 examples it is obvious that the label of
data points are not independent of each other. This idea is the motivation for us to explore new methods, which consider the dependencies between nodes in a graph. These methods are named "relational classification methods." Our goal is to solve the collective classification problem when the labels of objects are related to each other. |
 Figure 1. A friendship graph
|
Approach
There are various methods to solve the relational classification problem. Since in general the exact solution of these problems is NP-hard, the presented methods will be the approximate solution to this problem. These algorithms use different heuristics and different approaches. These methods have global or local approaches. In this project we implemented two machine-learning methods one with local approach and one with global approach, to classify not fully observed networks. It means that we do not know the label of more than one node in the network. Before explaining the classification method let us define the problem in a formal way.
Collective classification is a combinatorial optimization problem. We have a graph as an input, therefore the nodes in the graph V={v1,v2,...vn} are the objects and we also know the neighborhood function N which specifies the neighbors of each object. We assume each object in a graph to be a random variable, which can take a value in its domain. We also assume the set of random variables V divided into 2 sets of observed variables X and unobserved variable Y. Our problem is finding the correct label of unobserved data set Y in the graph.
Iterative Classification (Local approach)
The idea of Iterative Classification Algorithm (ICA) is very simple. For each $y_i \in Y$ we modify the feature vector corresponding to it as fallows (Figure 2):1 - A = The vector of attributes of the objects.
2- L = The vector of labels of object's neighbors. The length of this vector is equal to number of different labels in dataset. Each element of this vector refers to a label and denote the number of neighbors of that objects which have that label.
3- The feature vector F is the concatenation of A and L as we can see in Figure 2.
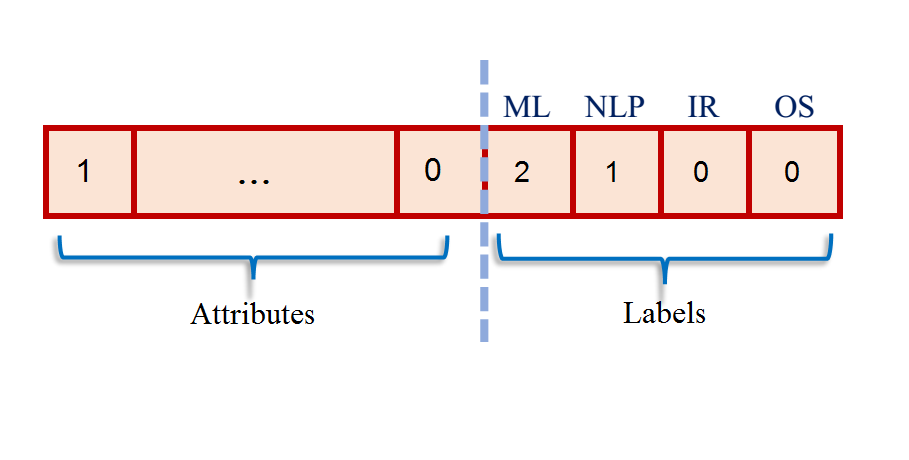 Figure 2. Feature vector in ICA
|
 |
The algorithm of ICA is as fallows:

The implementation was done in Matlab, which is available here. (ICA and Feature Modification)
Loopy Belief Propagation (Global approach)
In this project loopy belief propagation (LBP) was applied to pairwise MRF which is a message passing algorithm and we computed each massage as fallows: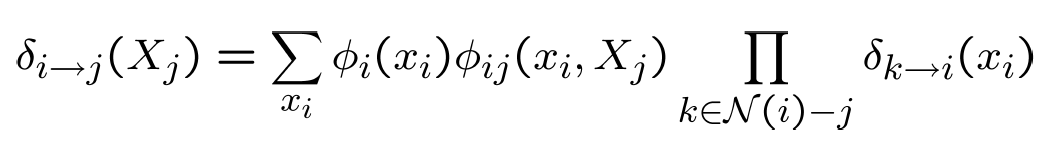
The implementation was done in Matlab which is available here.
Snowball sampling method
| In
order to construct the test and train sets we used snowball sampling
evaluation strategy (SS) to become sure there is sufficient number of
observed data for each node. As we can see in Figure 3 we start from a
random node in a graph and then expand our sampling by sampling from
neighbors of observed nodes. The implementation was done in Matlab, which is available here. |
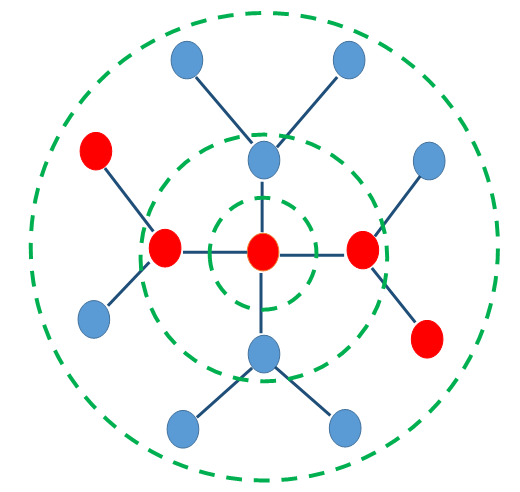 Figure 3 An overview of snowball sampling
|
Results
Dataset
|
In
this project we used the Cora dataset, which consists of 2708 Machine
Learning papers. These papers are classified into one of the following
seven classes: * Case_Based * Genetic_Algorithms * Neural_Networks * Probabilistic_Methods * Reinforcement_Learning * Rule_Learning * Theory publications classifed into For each paper there is a feature vector of size 1433, which corresponds to a word. An element in a vector is one if the corresponding word has appeared in the paper otherwise it is 0. The graph of data set is a directed graph and each edge between apair of papers means paper 1 cited paper 2. The citation network consists of 5429 links. Figure 4 is a representation of the graph, which was computed using Gephi application You can find the dataset here. |
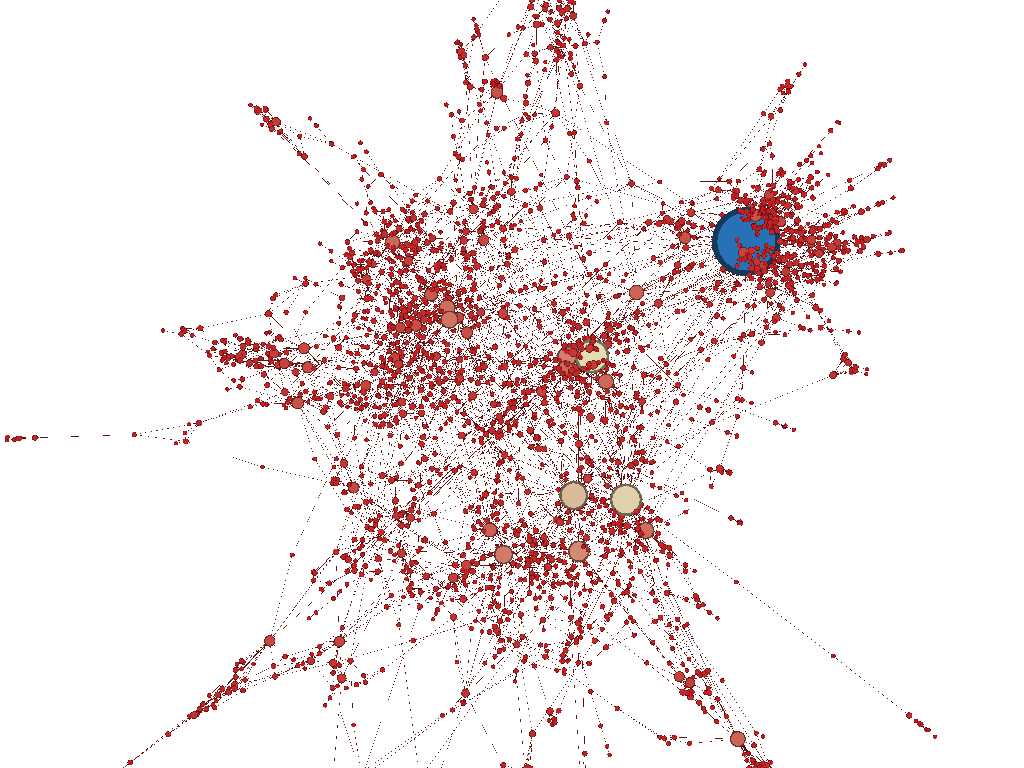 Figure 4. A visualization of Cora dataset
|
| Figure 5 denotes the achieved accuracy using different
classification methods. The first observation in the results is
that relational learning methods perform much better than content based
learning algorithms. The next observation is that changing the base
classifier does not affect the results of ICA method. Figure 6 shows the obtained accuracy of LBP algorithm with different penalty rates. In some cases we saw that ICA did not converge (Figure 7). |
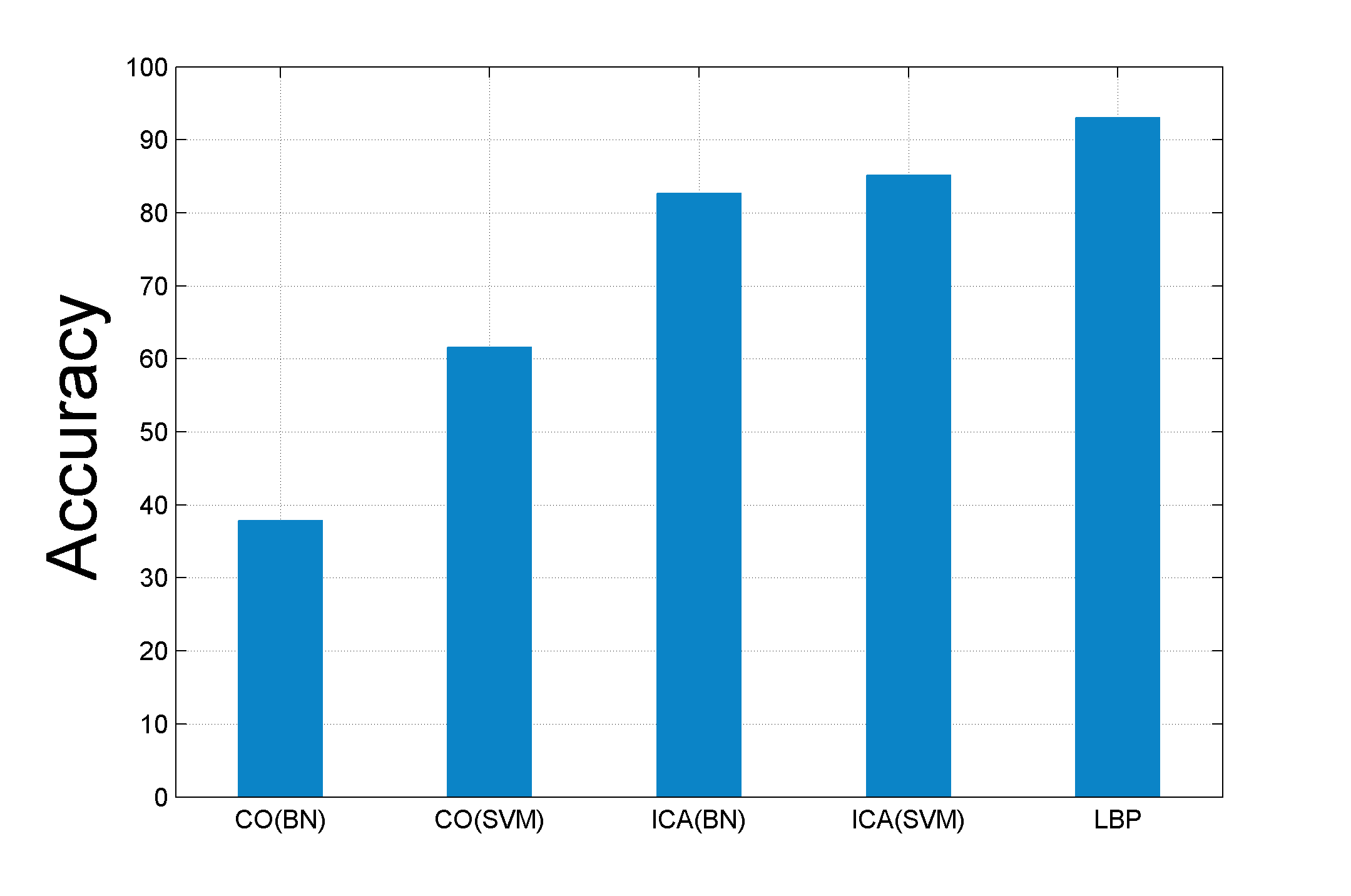 Figure 5. Achieved accuracy using different classification methods |
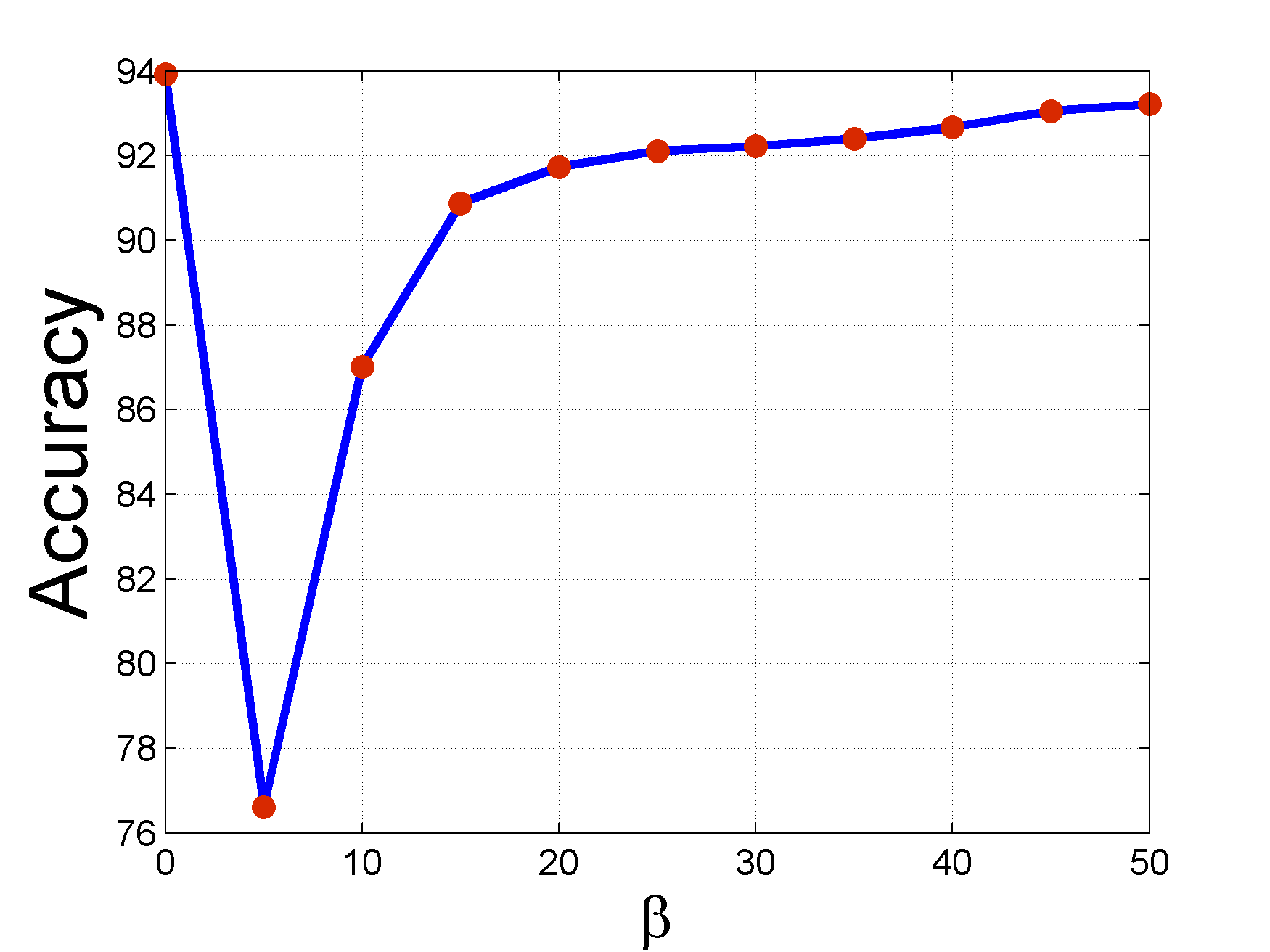 Figure 6. Results with different penalties in LBP algorithm
|
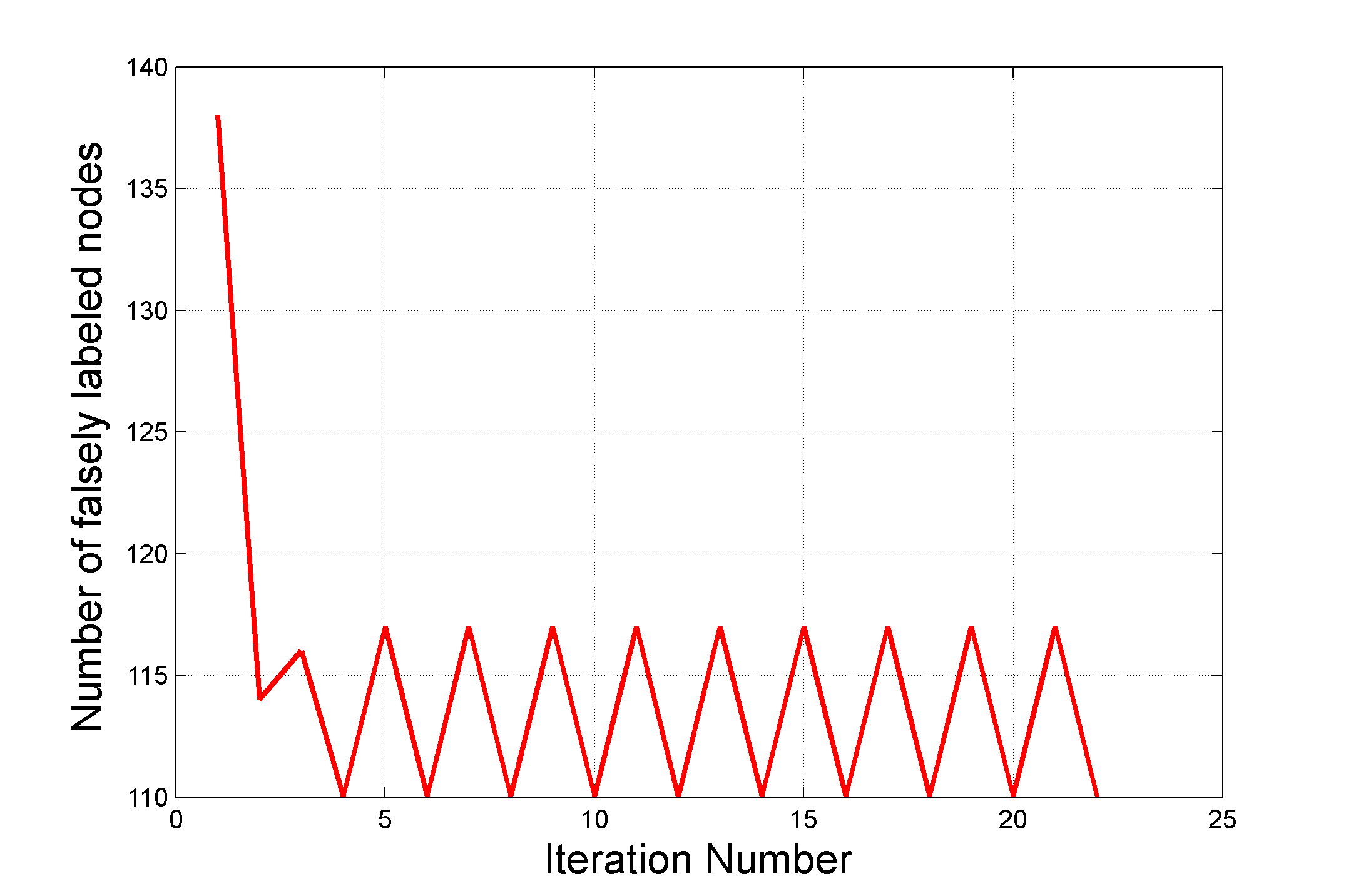 Figure 7. An example of ICA algorithm when it did not converge
|
© Sorour Ekhtiari Amiri