Topic Modeling For Wikipadia Pages
Abdullah AlfaddaSpring 2014 ECE 6504 Probabilistic Graphical Models: Class Project
Virginia Tech
Goal
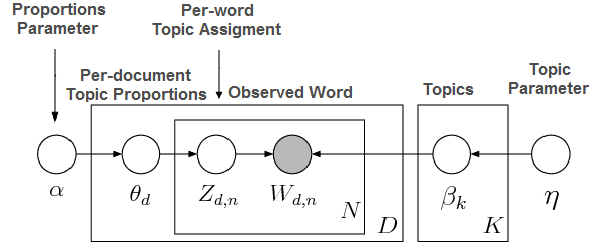
The main goal of this project is to compare different methods used in topic modeling.The baisc idea is to use the latent Dirichlet allocation (LDA) as a main component in the implementation. In order to compute the conditional probability of the LDA various methods are used. Generally they are categorized as Sampling-Based and Variational methods. For the Sampling-Based methods Collapsed Gibbs Sampling (CGS) was deployed and tested on random Wikipedia pages. On the Variational methods side, the Online LDA (OLDA), which implements a stochastic optimization approach, was deployed and tested against the CGS, under the same data-sets, and for different number of topics.
Approach
At first, different sizes of random wikipedia pages have been collected, of sizes 1000, 3000, and 5000 documents. Then the qunique words for each dataset was created, so that the words that are present frequently have been included. Also the common words that does not contribute to the model have been excluded (i.e. he, she ,it,...). Finally the CGS and OLDA have been tested over these datasets for different number of topics. The evaluation criteria of the results follow the basic one proposed here, by using perplexity on the held out-data as a measure of model fit.Results
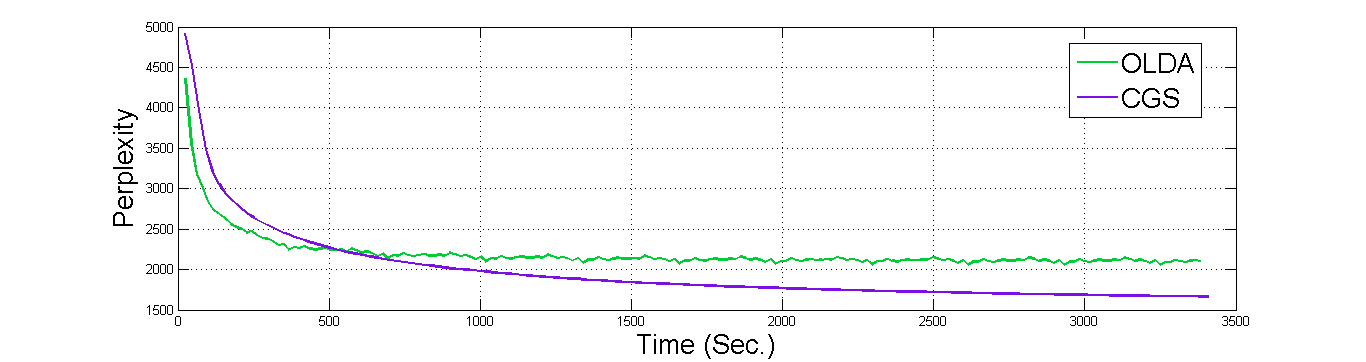
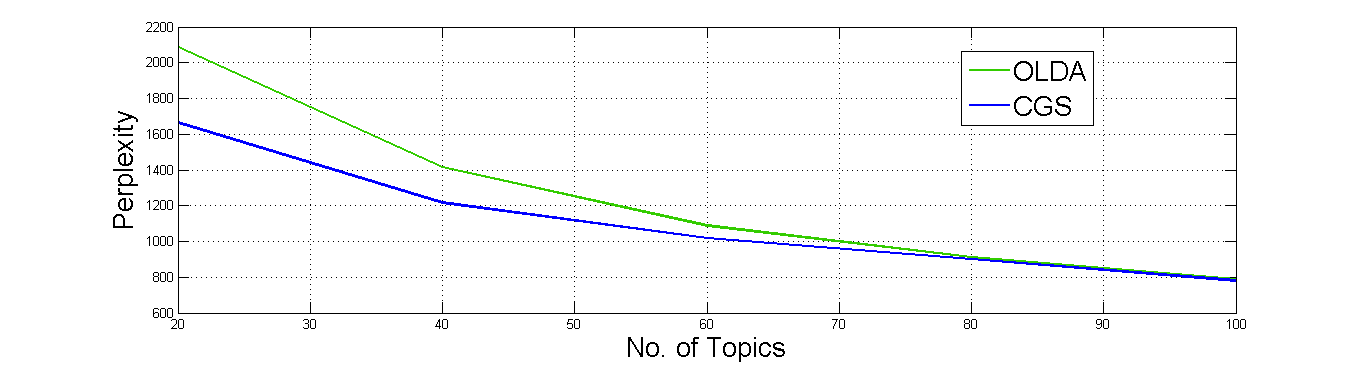
The first figure [1] shows a combarision between the CGS and OLDA in time and preplexity, under 20 topics, 1000 documents, α = 0.01 and β = 0.01. Clearly the OLDA converges much faster than the CGS. However, CGS performs better in terms of perplexity under this data set. Figure [2] show the results for running OLDA and CGS over differnt number of topics, while the number of docuemtns is 1000, as it is clear when the number of topics increase the perplixity decreases for both. However, the perplexity difference between the two algorithms decreases, and the OLDA and CGS converges to the same perplexity when the number of topics is 80 and more. The last figure shows samples of the topics produced by both OLDA (to the left) and CGS (to the right), for 20 topics and 1000 documents.