Shadow Detection and Removal from RGB Images
Suprotim Majumdar and Harsh Patel
Virginia Tech
Abstract
Teaser figure


Introduction
Recently, a method for removing shadows from color images was developed [Finlayson, Hordley, Lu, and Drew, PAMI2006] that relies upon finding a special direction in a 2D chromaticity feature space. This “Invariant Direction” is that for which particular color features, when projected into 1D, produce a grayscale image which is approximately invariant to intensity and color of scene illumination. Thus shadows, which are in essence a particular type of lighting, are greatly attenuated.
The main approach to finding this special angle is a camera calibration: a color target is imaged under many different lights, and the direction that best makes color patch images equal across illuminants is the invariant direction.
Using a different approach, producing a 1D projection in the correct invariant direction will result in a 1D distribution of pixel values that have smaller entropy than projecting in the wrong direction. The reason is that the correct projection results in a probability distribution spike, for pixels all the same, except differing by the lighting that produced their observed RGB values and therefore lying along a line with orientation equal to the invariant direction.
The approach we have taken involves detecting shadows in the image first and then change the R,G,B values of the pixels such that it is as illuminated as the rest of the image.
Approach
- Convert the image from RGB space to LAB space, where L is lightness component and, A and B are color-opponent dimensions, based on nonlinearly compressed coordinates.
- The L channel has values ranging from 0 up to 100, which corresponds to different shades from black to white. Since the shadow regions are darker and less illuminated than the surroundings, it is easy to locate them in the L channel since the L channel gives lightness information.
- Then we create a shadow mask by thresholding.
- We take the input from the user regarding how many shadows the user want to remove. Based on the input i.e. number of shadows to be removed, the user is asked to select a shadow region. Region Growing is used to get the desired shadow mask from the image.
- Then the user is asked to select a small non-shadow from the image. This is used as the desired RGB model based on which we perform shadow removal.
- Shadow removal is done by multiplying R, G and B channels of the shadow pixels using
appropriate constants. The ratio of the average intensities of pixels in each channel in the
selected non-shadow region to that in the shadow region is taken as a constant for each
channel. The shadow regions achieve almost the same illumination as the non-shadow regions.
Least Squares method is used to reduce the error in constant estimation.
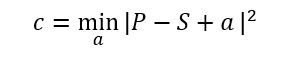
Where P is the region outside the shadow, S is the shadow region, c is the constant that the shadow region is multiplied by. - Also, we know that outdoor shadows are caused by an object occluding sunlight. We can then further constrain c to
- Since shadow regions are not uniformly illuminated, the same constant for the entire shadow region will create over-illuminated areas near the shadow edges. This is overcome by applying a median filter on the over-illuminated areas. Thus a shadow-free image without over-illuminated edges is obtained.
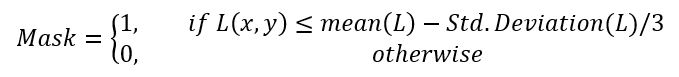
Experiments and results
Here are some results of the Invariant image that we obtained from the images taken off the internet and copied from the pdf file:

We have limited our inputs to outdoor images which have shadows caused by an object occluding sunlight. The algorithm works better with objects that are not dark in comparison to the shadow region. Also, the user is required to select a desired non-shadow region. As a consequence, results may vary subject to the user’s visual interpretation of the properties of the non-shadow region.
Qualitative results
Here are the results we obtained for some test images.
Figures (clockwise from top): Original Image, Shadow Image, Image Without Shadow, Image with artifacts at the edge of the shadow.
Image 1:
Image 2:
Image 3:
Failure Case:
Conclusion and Future Work
References
- Finlayson, Graham D., Mark S. Drew, and Cheng Lu. "Entropy minimization for shadow removal." International Journal of Computer Vision 85.1 (2009): 35-57.
- Finlayson, Graham D., et al. "On the removal of shadows from images." Pattern Analysis and Machine Intelligence, IEEE Transactions on 28.1 (2006): 59-68.
- Finlayson, Graham D., Steven D. Hordley, and Mark S. Drew. "Removing shadows from images." Computer Vision—ECCV 2002. Springer Berlin Heidelberg, 2002. 823-836.
- Drew, Mark S., Graham D. Finlayson, and Steven D. Hordley. "Recovery of chromaticity image free from shadows via illumination invariance." IEEE Workshop on Color and Photometric Methods in Computer Vision, ICCV’03. 2003.
- Xu, Li, Feihu Qi, and Renjie Jiang. "Shadow removal from a single image."Intelligent Systems Design and Applications, 2006. ISDA'06. Sixth International Conference on. Vol. 2. IEEE, 2006.
- Finlayson, Graham D., Mark S. Drew, and Cheng Lu. "Intrinsic images by entropy minimization." Computer Vision-ECCV 2004. Springer Berlin Heidelberg, 2004. 582-595.
- Drew, Mark S., Muntaseer Salahuddin, and Alireza Fathi. "A standardized workflow for illumination-invariant image extraction." Color and Imaging Conference. Vol. 2007. No. 1. Society for Imaging Science and Technology, 2007.
- Finlayson, Graham D., and Steven D. Hordley. "Color constancy at a pixel."JOSA A 18.2 (2001):253-264.
- Suny, Ashraful Huq, and Nasrin Hakim Mithila. "A Shadow Detection and Removal from a Single Image Using LAB Color Space." IJCSI International Journal of Computer Science Issues 10.4 (2013).
- Murali, Saritha, and V. K. Govindan. "Shadow Detection and Removal from a Single Image Using LAB Color Space." Cybernetics and Information Technologies 13.1 (2013): 95-103.
- Fredembach, Clement, and Graham Finlayson. "Simple Shadow Removal." Pattern Recognition, 2006. ICPR 2006. 18th International Conference on. Vol. 1. IEEE, 2006.